A few days ago I was assisting a Tamil customer with a Unicode keyboard they had designed which used visual input order. Visual input order means that vowels such as TAMIL VOWEL SIGN E, U+0BC6 ெ are typed before the consonant with which they combine, even though they are stored after the consonant as per the Unicode standard. Our customer was running into a problem where U+0BC6 ெ was combining with the wrong consonant in a run. In this blog I’ll discuss some of the possible solutions and potential issues with those solutions and finish with the solution that we proposed and that the customer chose to use. These solutions apply to any Indic script but we will use Tamil as an example.
The basic keyboard layout is shown below. For this discussion, I’ve only populated 3 keys – E, A and K. So you won’t be seeing real words in this example – the examples have been chosen as the simplest way to illustrate rendering complexities, and not as valid Tamil text.
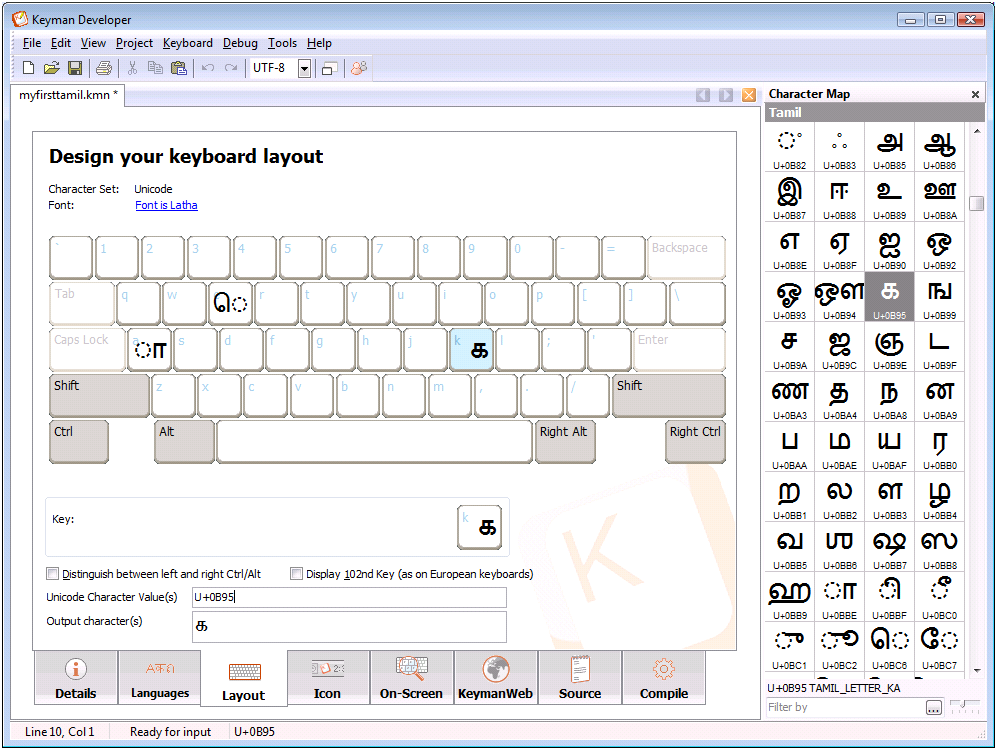
The Keyman source file looks like this:
store(&VERSION) '8.0' store(&NAME) 'My First Tamil Keyboard' store(&MESSAGE) 'Demonstrating Visual Input Order' begin Unicode > use(main) group(main) using keys + 'a' > U+0BBE + 'e' > U+0BC6 + 'k' > U+0B95
Now with this visual input order keyboard, the Tamil vowel U+0BC6 ெ is stored after the consonant in the document but typed before it. The keyboard as it stands won’t do that:
|
Typed |
Expected Display |
Actual Display |
Text Stored |
|
e |
ெ |
ெ |
U+0BC6 |
|
ek |
கெ |
ெக |
U+0BC6 U+0B95 |
The initial solution was to add a rule to reorder these:
U+0BC6 + 'k' > U+0B95 U+0BC6
This fixes the initial issue but introduces the Travelling Vowel Problem – a vowel that just won’t stay where it is put:
|
Typed |
Expected Display |
Actual Display |
Text Stored |
|
e |
ெ |
ெ |
U+0BC6 |
|
ek |
கெ |
கெ |
U+0B95 U+0BC6 |
|
ekk |
கெக |
ககெ |
U+0B95 U+0B95 U+0BC6 |
|
ekkk |
கெகக |
கககெ |
U+0B95 U+0B95 U+0B95 U+0BC6 |
The problem here is how to tell that the U+0BC6 ெ has already been combined with a consonant to prevent it moving further down the text store. The solution initially chosen by our customer involved using U+200C ZWNJ to stop the vowel U+0BC6 ெ from moving along to the next consonant:
U+0BC6 + 'k' > U+0B95 U+0BC6 U+200C
This simple change stops the rule from matching repeatedly, because U+0BC6 ெ is no longer at the end of the context. But does that solve the problem completely?
|
Typed |
Expected Display |
Actual Display |
Text Stored |
|
e |
ெ |
ெ |
U+0BC6 |
|
ek |
கெ |
கெ |
U+0B95 U+0BC6 |
|
ekk |
கெக |
கெக |
U+0B95 U+0BC6 U+200C U+0B95 |
Okay, so this seemed to display just fine but behind the scenes we now had an extra U+200C ZWNJ in the text store which is certainly not ideal. Our customer noticed this when one application rendered U+200C ZWNJ as a space rather than zero width.
So what if we used Keyman’s deadkey functionality to not actually store a character in the text, but still flag that the vowel has been combined?
U+0BC6 + 'k' > U+0B95 U+0BC6 deadkey(combined)
|
Typed |
Expected Display |
Actual Display |
Text Stored |
|
e |
ெ |
ெ |
U+0BC6 |
|
ek |
கெ |
கெ |
U+0B95 U+0BC6 (dk) |
|
ekk |
கெக |
கெக |
U+0B95 U+0BC6 (dk) U+0B95 |
Success! Or is it? What happens when we type the following?
|
Typed |
Expected Display |
Actual Display |
Text Stored |
|
k |
க |
க |
U+0B95 |
|
ke |
கெ |
கெ |
U+0B95 U+0BC6 |
|
kek |
ககெ |
ககெ |
U+0B95 U+0B95 U+0BC6 (dk) |
|
kekk |
ககெக |
ககெக |
U+0B95 U+0B95 U+0BC6 (dk) U+0B95 |
Hey! We don’t want to combine with that consonant – this is a visual order keyboard! This could be called the Overenthusiastic Vowel Combining Problem. However, the text is stored correctly.
So that’s a rendering issue again. We can’t solve that with a deadkey statement. It looks like our customer was on the right track after all. The key to solving this is to remember that the uncombined vowel is an intermediate state. We can temporarily add a U+200B ZWSP before this vowel to stop it combining to the consonant, knowing that we can delete the U+200B ZWSP as soon as the combining consonant is typed, by changing two rules in the keyboard:
+ 'e' > U+200B U+0BC6 U+200B U+0BC6 + 'k' > U+0B95 U+0BC6
I chose U+200B ZWSP because it does not have any other shaping behaviour. Now when we type our test sequences, we get the following:
|
Typed |
Expected Display |
Actual Display |
Text Stored |
|
k |
க |
க |
U+0B95 |
|
ke |
கெ |
கெ |
U+0B95 U+200B U+0BC6 |
|
kek |
ககெ |
ககெ |
U+0B95 U+0B95 U+0BC6 |
|
kekk |
ககெக |
ககெக |
U+0B95 U+0BC6 U+0B95 U+0B95 |
I’ve highlighted in that table the U+200B ZWSP character that is stored temporarily to prevent the U+0BC6 ெ from combining with the previous character. Notice that U+200B ZWSP gets deleted in the next step. This simple pattern solves both the Overenthusiastic Vowel Combining Problem and the Travelling Vowel Problem.
Just for fun, I’ll add one final rule to handle the TAMIL VOWEL SIGN O, U+0BCA ொ. This is a combination of the U+0BC6 ெ and U+0BBE ா vowels, and is rendered on both sides of the consonant it attaches to. This ends up being a single, simple rule:
U+0B95 U+0BC6 + 'a' > U+0B95 U+0BCA
|
Typed |
Expected Display |
Actual Display |
Text Stored |
|
k |
க |
க |
U+0B95 |
|
ke |
கெ |
கெ |
U+0B95 U+200B U+0BC6 |
|
kek |
ககெ |
ககெ |
U+0B95 U+0B95 U+0BC6 |
|
keka |
ககொ |
ககொ |
U+0B95 U+0B95 U+0BCA |
The final keyboard is then:
store(&VERSION) '8.0' store(&NAME) 'My First Tamil Keyboard' store(&MESSAGE) 'Demonstrating Visual Input Order' begin Unicode > use(main) group(main) using keys + 'a' > U+0BBE + 'e' > U+200B U+0BC6 + 'k' > U+0B95 U+200B U+0BC6 + 'k' > U+0B95 U+0BC6 U+0B95 U+0BC6 + 'a' > U+0B95 U+0BCA
Using these design patterns, you can create visual input order keyboards for any of the Indic scripts, and you would transfer the same principles to phonetic input methods. Judicious use of the any, index and store statements will also make light work of handling all the possible combinations. Other considerations that I have not covered here include visual order backspacing and prevention of illegal combinations such as U+0B95 U+0BBE U+0BBE காா.
1 thought on “Techniques for Complex Script Keyboards – Visual Input Order”
Marc Durdin · February 11, 2011 at 9:13 am
As noted by one reader, in the final 3 examples, the first Tamil Letter K U+0B95 depicted is shown as a consonant from a previous syllable. In practice this issue may rarely arise but for the prevention of confusion by the unexpected reordering of vowels, it is still useful to do this.